
Corpus access
Access VOICE 3.0 Online here.
VOICE is a computerized open-access corpus capturing more than one million words of naturally-occurring, spoken English as a lingua franca (ELF) interactions.
Access VOICE 3.0 Online here.

The Vienna-Oxford International Corpus of English (VOICE) is a collection of language data, the first computer corpus capturing spoken English as a lingua franca (ELF) interactions.

Recommended and short citations

VOICE, the Vienna-Oxford International Corpus of English, is a structured collection of language data, the first computer-readable corpus capturing spoken ELF interactions of this kind.

Find information on the possible search options in VOICE 3.0 Online here.

Get informed on the VOICE mark-up and spelling conventions.

Access for information on the POS tagging and lemmatization of VOICE.

Click here to access the VOICE 3.0 Online tutorial materials.

Watch our tutorial videos to find your way around VOICE 3.0 Online.
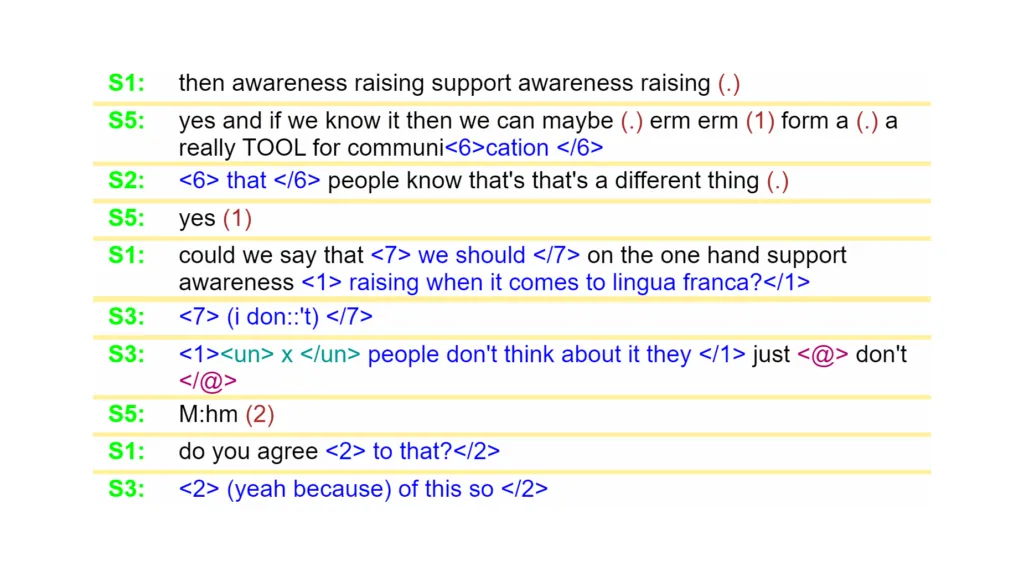
The main aim of the VOICE CLARIAH project is to update and enhance the web interface of VOICE (Vienna-Oxford International Corpus of English) in order to ensure its long-term availability as an open-access resource for the description of spoken English as a lingua franca (ELF) to researchers worldwide. The project updates and improves the system architecture behind VOICE Online, relying on VOICE XML and VOICE POS XML, to support the existing online applications of the corpus with new tools. A second goal is to integrate VOICE into the CLARIAH-AT infrastructure to guarantee continued and stable access for corpus users.
The VOICE CLARIAH project is a co-operation between the the Austrian Centre of Digital Humanities and Cultural Heritage (ACDH-CH) at the Austrian Academy of Sciences (ÖAW) and Department of English and American Studies of the University of Vienna. The group of researchers working on the integration of VOICE into the CLARIAH-AT infrastructure and the development of the new VOICE Online web interface is committed to ensure the continued, updated, open-access and user-friendly availability of VOICE data for international scholars.